Let’s Make a Voting System
Last updated .
Contents
Ludum Dare is a grueling, 48-hour game development competition. Think of it a triathlon spent in front of a computer screen: each participant has to master game design, programming, and media creation. Almost everything has to be created from scratch during the 48 hours. Failure is common.
However, the contest is an undeniable success. The 23rd Ludum Dare saw over 1,400 successful participants, which creates a logistical headache: after the contest, the entries are ranked in several categories, and winners are identified. Sorting through 1,400 entries and rating them takes even more time than the contest itself!
Voting System
- Games are rated in nine categories: innovation, fun, theme, graphics, audio, humor, mood, overall, and community.
- Only successful participants may vote.
- Each vote may assign a rating, from 1–5, in each category to a game.
- Each game is scored according to the average rating in each category.
We can identify this as a simple range voting.
In this article, I sometimes draw a distinction between “rating system,” which refers to the system that generates ratings from 1–5, and “ranking system,” which refers to the system that generates rankings #1, #2, #3,…,#1402.
Voting Accuracy
Posters on the Ludum Dare website and others have identified the voting system as “unfair” for a number of reasons.
- Some games are difficult to run, so they are scored by a small number of people. If you release a game for the NEC PC-8801, and all your friends in the PC-8801 appreciation club give it high marks, you can get a very high score overall.
- Another claimed problem is that some people may be overly generous: if you give 4-5 stars to most of the games you play, and another person gives 2-3 stars to most games, then the net effect has a poor signal-to-noise ratio. Put another way: if everyone’s voting style is too different, then the result depends more on who votes on each game than it does on the quality of the game.
Are these concerns reasonable? Can we create a system that addresses these concerns?
The Reason We Vote
Before we can address concerns about the voting system, we have to understand why the voting system exists in the first place. For me, there are two reasons.
- Voting is a source of quantitative feedback about the games we make.
- Voting lets us find the “top” games after the contest ends.
Getting Quantitative Feedback
For me, the quantitative feedback holds wonderful possibilities. I want to know how people rated my game. For the record, here are the ratings for my game (original data):
| Category | Rating | Rank |
|---|---|---|
| Coolness | 71% | (bronze) |
| Innovation | 3.42 | #61 |
| Graphics | 3.63 | #77 |
| Overall | 3.29 | #100 |
| Humor | 2.68 | #108 |
| Theme | 3.25 | #155 |
| Fun | 2.63 | #236 |
| Mood | 2.41 | #314 |
| Community | 2.33 | #404 |
| Audio | 1.13 | #557 |
From this quantitative evaluation, I’ve gained some valuable feedback for my post-mortem analysis (it’s never to late for a post-mortem).
- Fun: The game was not very fun, comparatively. Duly noted! Atomic noted in the first comment “not very fun,” but SonnyBone said “This is really fun to play!” Without the numbers, I’d just accept SonnyBone’s comment and give myself a pat on the back. With the numbers, I know I’ll be asking myself, “Is this game fun?” When I compete next time.
- Graphics: The graphics were a success. Based on the feedback, I decided to continue doing graphics the same way, although I purchased some better markers. (Crayola marker black is really “dark puke green”, but my new Copic black is wonderfully bold.)
- Innovation: From the feedback, it looks like I spent about the right amount of time hashing out ideas for the game, but again, I should spend more time thinking “Is this fun?”
For me, these numbers are a great supplement to the comments. They make me feel confident about which areas I nailed and which areas I need to work on.
As a final note, I'm curious as to who rated my game’s audio as a “2” or higher. My game has no audio. Is a “1” reserved for “it makes my ears bleed”? A couple games I played did hurt my ears…
Finding Top Games
At the end of the contest, we want to see the best games. Kudos to whoever gets first place, of course. But I love looking at the top five or ten games. I like to download a cool game, play it, and get to say “I was a part of that.” Ranking the top games is not only a reward to the people who made those games, it is a reward to everyone who finds a fun game by looking at the rankings.
Does the System Work?
For giving quantitative feedback, I say, “Yes, it does work.” But there are problems with the ranking system when you consider how the top games are selected. We will need to do a little bit of math.
Let’s start by looking at the top three games for LD #23 in the “overall” category.
| Game | Votes | Rating |
|---|---|---|
| Fracuum | 119 | 4.43 |
| Memento | 216 | 4.39 |
| Super Strict Farmer | 81 | 4.37 |
These numbers are fairly convenient for us. For Fracuum, a rating of 4.43 means that some people gave a rating of 4 and some people gave a rating of 5, and maybe a few people gave 3 or lower. We can actually calculate a lower bound on the variance of the votes, assuming the average is correct: the minimum variance that gives an average of 4.43 occurs when 43% of the voters vote 4, and 57% of the voters vote 5. The minimum variance is then:
σ2min = 0.57 * (4.43 – 4)2 + 0.43 * (4.43 – 5)2 ≈ 0.25.
Note that the variance exists, and it’s bounded (because you can’t vote outside the range 1–5). This lets us employ the Central Limit Theorem to come up with an estimate for the distribution of the final average. Assuming that the votes are independent of each other, then the central limit theorem tells us that the distribution of the average rating X̅ is approximately:
X̅ ~ normal(µ, σ2/n)
- X̅: the observed average rating
- µ: the “true” average rating
- σ2: the variance of each vote
- n: the number of votes
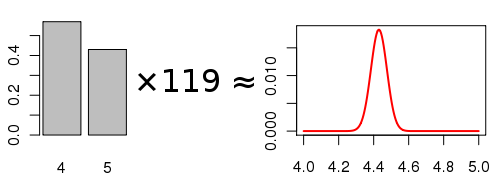
When we think about the distribution of the average vote, imagine running the contest over and over again, and plotting the results. Each time you run the contest, different people vote. When we think about the distribution of an individual vote, imagine selecting a person at random and asking them to vote this game.
By putting a lower bound on the variance for each individual vote, we get a lower bound on the variance for the average vote.
σ2/n ≥ σ2min/n = 0.25 / 119 = 0.0021.
We can do this for all the top games.
| Game | Votes | Rating | σ2/n |
|---|---|---|---|
| Fracuum | 119 | 4.43 | 0.0021 |
| Memento | 216 | 4.39 | 0.0011 |
| Super Strict Farmer | 81 | 4.37 | 0.0029 |
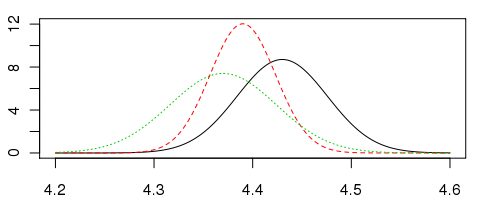
This lets us use normal distribution tables to answer the questions, What if Memento is really rated higher than Fracuum? What are the odds we’d still get the same results? What about Memento and Super Strict Farmer?
Well, we’re actually going to use a piece of software called R (www.r-project.org) to perform the calculations.
> pnorm((4.43 - 4.39) / sqrt(0.0021 + 0.0011)) [1] 0.76025 > pnorm((4.39 - 4.37) / sqrt(0.0011 + 0.0029)) [1] 0.6240852
Under this statistical model,
- If Memento’s true rating were actually higher than Fracuum’s, the chance of getting the results we actually got could be 24% or higher.
- If Super Strict Farmer’s true rating were actually higher than Memento’s, the chance of getting the results we actually got could be 38% or higher.
The likelihood distributions below show the amount of uncertainty in more vivid detail:
Discussion, and Fixes
Based on the high chances of error we obtained by analyzing our model (38% is very high!), we can conclude that the current ranking system is bad at selecting a winner. It is very plausible that if you were to run the voting again, you would get a different answer for first, second, and third place.
The reason this happens in our model is because people are forced to choose between giving a 4 and a 5 as a rating—it is impossible for everyone to agree and give a 4.43. The discrete ratings put a lower bound on the variance, at least in certain cases. Additionally, while I can’t answer whether some people simply vote generous or vote harsh, if this is true, then it increases the variance further and makes the final accuracy worse.
We can think of some possible solutions to the ranking system’s poor accuracy:
- Abolish ratings altogether. This was proposed by Folis in his July 30, 2012 blog post. I am against this, because I believe I benefit from having my game rated, even if nobody else gets to see the ratings. I also think this removes some of the encouragement people have to vote on games.
- Abolish rankings. The ratings could be private to whoever received them, or the ratings could be public but the actual rankings (#1, #2, #3, etc.) could be removed from the website.
- Increase rating accuracy. If we increase the accuracy of the ratings, we also increase the accuracy of the rankings. For example, we could allow people to give ratings in increments of 0.1, which in theory would cut down the error by a factor of 10. The problems with this approach are fairly obvious: people are bad at giving ratings with such fine gradation. Analysis of the data could also allow us to lower error by identifying voting biases, but I believe this is also a lost cause.
- Create a new ranking system.
Reasons to Vote
In my uninformed opinion, one of the strengths of the current system is that it actually encourages people to play games. We don’t just play games because we want to give feedback to the game developers, we also play games because we are hungry to see which games made it into the top ranks!
If voting on games didn’t have such a draw, if we eliminated voting altogether or even got rid of the rankings, I predict that the number of games played would drop.
Alternative System Proposal
I propose a two phase system which keeps the benefits of the current system, and provides a more accurate ranking for the top games in each category. The system works in two phases.
The first phase of the system works exactly as the voting does now. Everyone plays everyone else’s game, and rates the games in each category. This phase is important to our community because the rating system ensures that everybody’s game gets played at least a few times, and you’re likely to get a couple good comments about your game.
The second phase is the “Ludum Dare finals.” The top 10 or so of the games are selected for the finals pool, and voters rank them relative to each other. This would require a completely new voting interface. Voters don’t have to rank all of the games in the final round, and ties are permissible.
The final ranking is determined using the ranked pairs method. For each game that a voter ranks, the vote counts as a vote for that game against every game that the voter ranks lower. The votes are tallied as pairs, so if I rank games A B C, then that counts for 1 vote A over B, 1 vote A over C, and 1 vote B over C. All the pairs are tallied and a final ranking is constructed by repeatedly adding the pair with the most votes to the final ranking, until a cycle is created in the ranking graph.
The advantages of this system:
- This system is designed to produce a ranking.
- Not every voter needs to vote on every game.
- Games neither benefit nor are they penalized for voters who don’t play them (on average).
- This system forces voters to think about the games in comparison to each other.
Disadvantages:
- The voting system requires implementation.
- Voters may be tired of voting by the final round. However, they may be excited to play the games in the final round, since they will all be good.
- It is probably too much to ask of voters to rank a dozen games in several categories. The final round should probably be for “overall” only.
Conclusion
I’ve showed that the existing system is a bit too inaccurate for the large number of games in recent competitions. With so many games and no accurate ranking system, the idea of ranking them is farcical, which is not fair to the participants.
The alternate system requires a bit of work (I can help!), but keeps most of the benefits of the existing system.
Feedback
I don’t have a comment system here, but you can reply to the post on the Ludum Dare blog: (Shall we vote?), or shout at me on Twitter (@DietrichEpp).